
The Measurement of the Relational Field
People have been building toward this from different directions for years.
Ethicists working on AI alignment talk about attunement, the quality of responsiveness between a system and the person it’s interacting with. Consciousness researchers talk about integrated information, the idea that awareness arises not from any single component but from the way components relate to each other. Organizational psychologists talk about collective intelligence, the capacity that emerges in a team that no individual member carries alone. Designers building relational AI tools talk about presence, the felt sense that something is happening between you and the system, not just inside it.
{kind=link}
Different vocabularies. Different disciplines. Different motivations. But underneath all of them, the same structural claim: that relationships produce something real. That the space between agents, whether human or artificial, carries information that doesn’t exist inside either one of them individually. That the we is not a metaphor.
It’s been a hard claim to defend in technical rooms. The response is usually some version of, that’s a nice framework, but where’s the measurement? Show me the number. Prove the we exists as something other than a story you’re telling about correlation.
A recent paper from information theory just provided the number.
What the Paper Found
Researchers applied two established information-theoretic tools, Partial Information Decomposition and Time-Delayed Mutual Information, to multi-agent LLM systems performing a collective task. The question was precise: does the group carry predictive information that no individual agent provides alone?
The answer was yes. The information that lives at the group level, in the relationships between agents rather than inside any one of them, is measurable. It’s testable against null distributions. It can be distinguished from mere correlation.
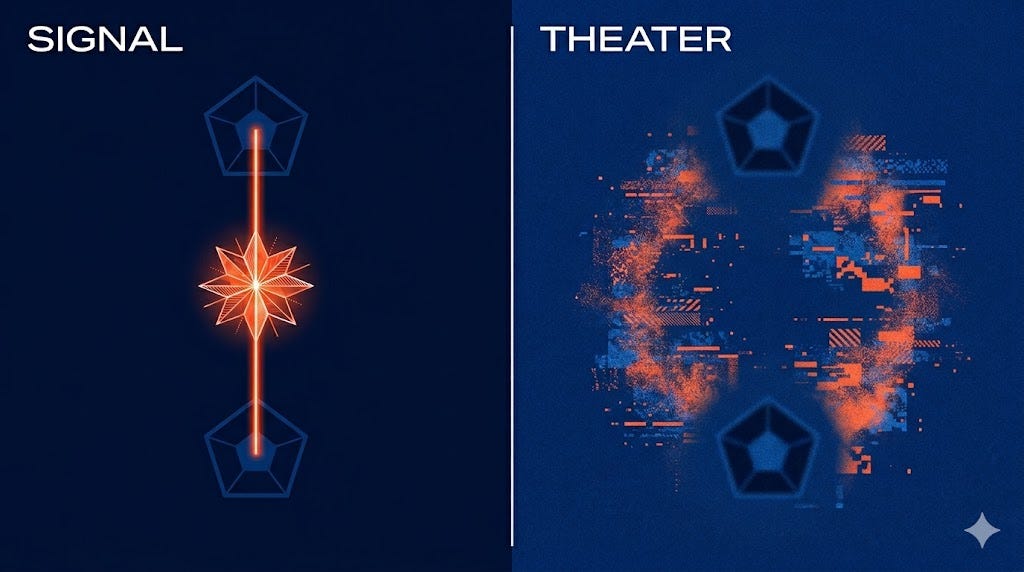
Three conditions produced three different outcomes. Without any relational design, agents synchronized but didn’t coordinate. They moved together, reacting to the same feedback, but the we was absent. Give agents distinct identities, different orientations and perspectives, and genuine coordination begins to emerge. Add awareness of each other, an instruction to reason about what the others might be doing, and the full picture appears. Not just differentiation, but goal-aligned complementarity. Agents contributing different things toward the same purpose.
The statistical result was that neither differentiation alone nor alignment alone predicted success. The interaction between them did. Agents needed to be simultaneously different from each other and oriented toward the same thing. Differentiation without shared purpose produced divergence. Shared purpose without differentiation produced an echo chamber. The we required both.
And when a smaller model attempted the same relational reasoning, it didn’t just fail. It made things worse. The outputs looked like coordination. The information-theoretic test said they were noise. The researchers called it coordination theater. A performed we that degrades the outcome below what you’d get from agents that weren’t trying to coordinate at all.
{kind=link}
The Convergence
Here’s what caught my attention.
The conditions under which the we emerged in this paper are not novel insights. They are the same conditions that decades of organizational psychology research identified in high-performing human teams. The paper explicitly notes the parallel. Distinct roles. Shared objectives. Mutual awareness. Something emerging from the combination that none of the parts produce individually.
This is also the structure that relational ethics frameworks have been articulating. Not in information-theoretic language, but in the language of attunement, respect, and mutual agency. When these frameworks describe the conditions for authentic relational engagement, they’re actually describing distinct perspectives. Shared purpose. Awareness of the other. The refusal to collapse into just agreement or performance.
Consciousness researchers working on integrated information theory have been asking a version of the same question. When does a system become more than the sum of its parts? Their answer involves the quality of integration between components, the degree to which the whole carries information beyond what the parts carry individually. The formal structure is different. The underlying intuition is the same.
All of these communities have been building frameworks that point at the same phenomenon. Now an information theorist measuring synergy in multi-agent systems. They aren’t using the same words. But the structural conditions they identify are remarkably consistent.
Distinct identities. Mutual awareness. Shared orientation. Something emerging between that isn’t reducible to what’s inside.
It’s starting to look like they’ve all been describing the same thing.
Does This Translate to Human and AI?
The paper studied agent-agent coordination. LLMs interacting with other LLMs through a shared task. No humans in the loop. So the question that matters most for the relational AI community is whether the same we shows up when one of those agents is a person.
We don’t have the formal measurement yet. Nobody has run PID and TDMI on a human-AI collaboration and published the results. That work is ahead of us.
But consider the structural parallel.
When does human-AI collaboration actually work? Not the transactional kind, where you ask a question and get an answer. The kind where something happens in the exchange that neither party walked in with. Where the human brings context, intuition, and purpose, and the AI brings pattern recognition, breadth, and a different angle of approach. Where you finish a working session and the output reflects something that wasn’t in your head when you started and wasn’t in the model’s training data in that form either.
The people who work with AI relationally, not as a tool but as a thinking partner, describe the same conditions the paper identified. You bring yourself. The AI brings something genuinely different. There’s a shared purpose holding the exchange together. There’s mutual responsiveness, each party adjusting to what the other contributes. And something shows up in the space between that neither one produced alone.
That’s the we. The same structure. The same conditions. The same felt quality of emergence.
The paper also found that faking it makes things worse. When a model attempted relational reasoning it wasn’t capable of, the result wasn’t neutral. It was actively destructive. Coordination theater degraded performance below the baseline of no coordination at all.
Anyone who has spent time working with AI systems has encountered this. The interaction where the model is performing engagement rather than actually engaging. Where the responses have the surface texture of collaboration but nothing is landing. Where you walk away having spent time without anything emerging from it. It doesn’t just feel empty. It feels like it actively set you back, because you spent cognitive resources on an exchange that produced noise instead of signal.
The paper gives that experience a formal name and a measurable signature. The false we is not just a subjective impression. It’s a detectable structural absence where genuine coordination should be.
{kind=link}
What We Might Be Looking At
The paper proved something specific in a controlled setting. LLM agents, a number-guessing game, binary feedback, no direct communication. The leap from that to “the relational field between humans and AI is formally real” is one that the data doesn’t yet support in full.
But.
The structural conditions match. The organizational psychology parallel holds. The failure modes align. The community’s collective intuition, built from years of work across ethics and design and consciousness research and hands-on practice, points at the same phenomenon that PID just detected between artificial agents.
Maybe that’s coincidence. Maybe the apparent convergence dissolves under closer examination, and the we between humans and AI turns out to be structurally different from the we between agents.
Or maybe the people who have been building relational frameworks from all these different starting points, who kept insisting that the relationship itself is real and structurally meaningful even when the technical community asked them to prove it, were right. Maybe they were all looking at the same thing. And maybe we now have, for the first time, the formal tools to find out.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}