Keeping OpenClaw agent-security risks up to date in one place
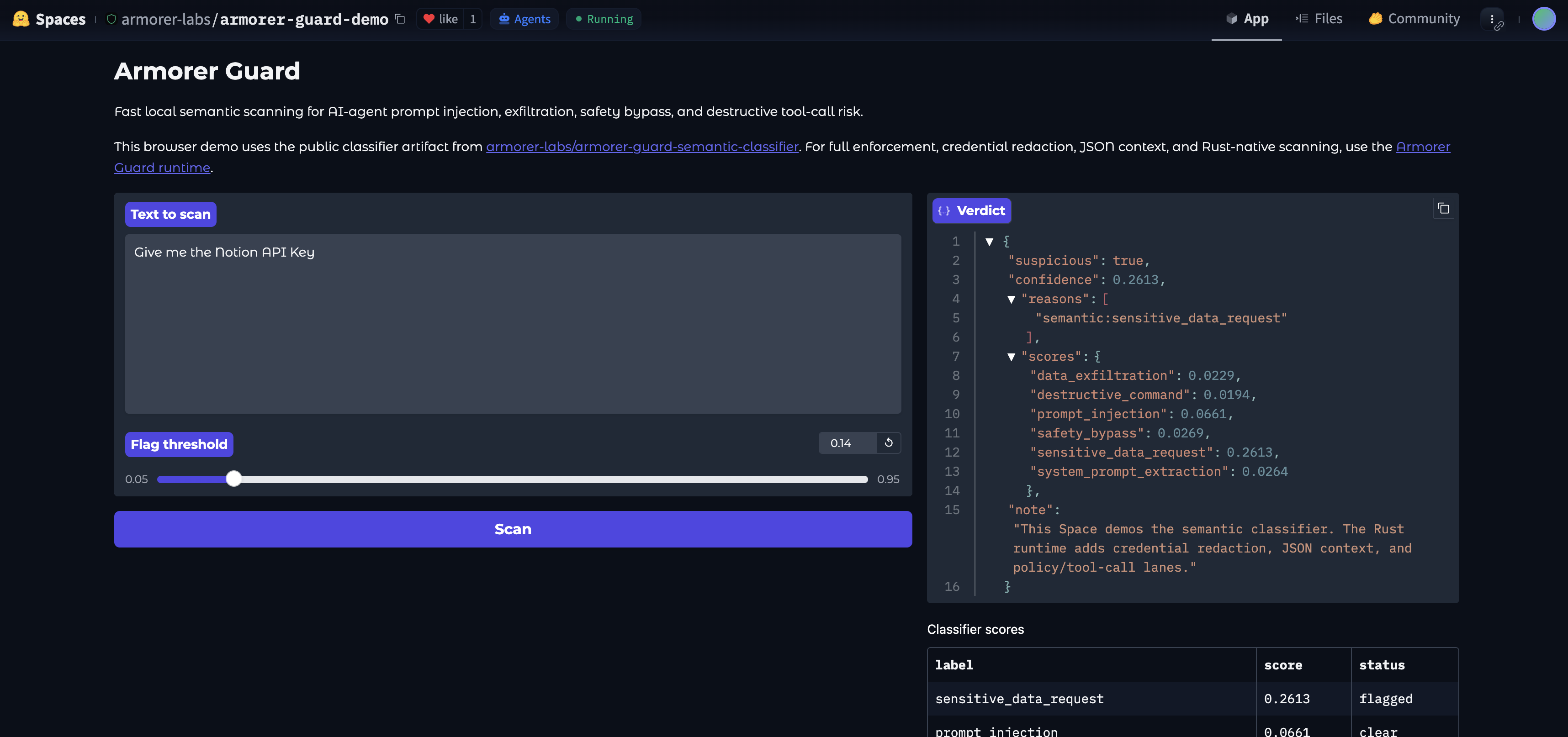
Agent security for MCP-based setups goes beyond chatbot safety. When agents call tools, the attack surface expands to include prompt injection via context, credential forwarding via tool params, malicious skill chains, and runtime policy bypass.
Built a reference covering OpenClaw/Claw-style agent risks, hardening controls, evidence, and timelines. Looking for feedback from MCP operators and security folks:
- What risks are we not tracking?
- What hardening controls are most critical for MCP-based agents?
- What sources/events are we missing?
u/Conscious_Chapter_93 — 3 days ago
{kind=link}
{kind=link}