▲ 0 r/compsci
Beyond Binary: The Mathematical Efficiency of Ternary Computing
ponderwall.comu/Akkeri — 10 hours ago
Hello, I'd like to share misa77, a codec I've been working on for some time now.
Source Code: https://github.com/welcome-to-the-sunny-side/misa77
misa77 is a LZ-based codec that targets the write-once, read-many niche. In particular, it aims to satisfy the following criteria:
Slow compression is the obvious tradeoff that one makes to achieve the above.
In addition, misa77 has a somewhat synergizing tendency to decompress highly compressed files faster, leading to the following results:
This makes high-effort compression particularly attractive for misa77, and inspires some experimental compression modes that aim to spend more effort at compression time to produce a compressed stream that is friendlier to the microarchitectures of most CPUs when decompressing said streams. As of v0.1.0, there are two experimental compressors:
misa77::experimental::adaptive_compress for homogeneous data.misa77::experimental::yolo_compress, which is more general-purpose and has lesser overhead than (1).Detailed results are listed ahead, but here's a terse summary:
All benchmarks were run using https://github.com/welcome-to-the-sunny-side/lzbench (fork of lzbench) and can be reproduced easily. For the codecs below, I've used flags that yield a similar compression ratio to misa77.
Details:
performance.| Compressor name | Compression | Decompress. | Ratio | Filename |
|---|---|---|---|---|
| misa77 0.1.0 | 43.9 MB/s | 4285 MB/s | 39.62 | silesia.tar |
| misa77 0.1.0 yolo | 7.68 MB/s | 5513 MB/s | 42.75 | silesia.tar |
| lz4 1.10.0 | 370 MB/s | 2512 MB/s | 47.59 | silesia.tar |
| lz4hc 1.10.0 -12 | 7.31 MB/s | 2534 MB/s | 36.45 | silesia.tar |
| lizard 2.1 -10 | 323 MB/s | 2452 MB/s | 48.79 | silesia.tar |
| lzsse4fast 2019-04-18 | 186 MB/s | 2538 MB/s | 45.26 | silesia.tar |
| lzsse8fast 2019-04-18 | 183 MB/s | 2668 MB/s | 44.80 | silesia.tar |
| zxc 0.12.0 -3 | 115 MB/s | 2839 MB/s | 45.46 | silesia.tar |
| zxc 0.12.0 -4 | 81.0 MB/s | 2727 MB/s | 42.63 | silesia.tar |
| zxc 0.12.0 -5 | 48.7 MB/s | 2599 MB/s | 40.25 | silesia.tar |
| zstd 1.5.7 -1 | 297 MB/s | 902 MB/s | 34.54 | silesia.tar |
| snappy 1.2.2 | 376 MB/s | 857 MB/s | 47.89 | silesia.tar |
Details:
| Compressor name | Compression | Decompress. | Ratio | Filename |
|---|---|---|---|---|
| misa77 0.1.0 | 71.3 MB/s | 6220 MB/s | 39.62 | silesia.tar |
| misa77 0.1.0 yolo | 13.7 MB/s | 7832 MB/s | 42.75 | silesia.tar |
| lz4 1.10.0 | 693 MB/s | 4455 MB/s | 47.59 | silesia.tar |
| lz4hc 1.10.0 -12 | 12.8 MB/s | 4326 MB/s | 36.45 | silesia.tar |
| lizard 2.1 -10 | 573 MB/s | 2887 MB/s | 48.78 | silesia.tar |
| lzsse4fast 2019-04-18 | 323 MB/s | 4195 MB/s | 45.26 | silesia.tar |
| lzsse8fast 2019-04-18 | 311 MB/s | 4416 MB/s | 44.80 | silesia.tar |
| zxc 0.12.0 -3 | 213 MB/s | 4935 MB/s | 45.99 | silesia.tar |
| zxc 0.12.0 -4 | 151 MB/s | 4776 MB/s | 43.04 | silesia.tar |
| zxc 0.12.0 -5 | 87.3 MB/s | 4570 MB/s | 40.29 | silesia.tar |
| zstd 1.5.7 -1 | 491 MB/s | 1598 MB/s | 34.55 | silesia.tar |
| snappy 1.2.2 | 691 MB/s | 1355 MB/s | 47.85 | silesia.tar |
Details:
| Compressor name | Compression | Decompress. | Ratio | Filename |
|---|---|---|---|---|
| misa77 0.1.0 | 94.3 MB/s | 10007 MB/s | 39.62 | silesia.tar |
| misa77 0.1.0 yolo | 17.1 MB/s | 13088 MB/s | 42.75 | silesia.tar |
| lz4 1.10.0 | 881 MB/s | 5173 MB/s | 47.59 | silesia.tar |
| lz4hc 1.10.0 -12 | 17.0 MB/s | 4874 MB/s | 36.45 | silesia.tar |
| zxc 0.12.0 -3 | 276 MB/s | 8010 MB/s | 45.77 | silesia.tar |
| zxc 0.12.0 -4 | 192 MB/s | 7628 MB/s | 43.20 | silesia.tar |
| zxc 0.12.0 -5 | 114 MB/s | 7126 MB/s | 40.30 | silesia.tar |
| snappy 1.2.2 | 966 MB/s | 3438 MB/s | 47.91 | silesia.tar |
| zstd 1.5.7 -1 | 714 MB/s | 1614 MB/s | 34.54 | silesia.tar |
| lizard 2.1 -10 | 830 MB/s | 6530 MB/s | 48.78 | silesia.tar |
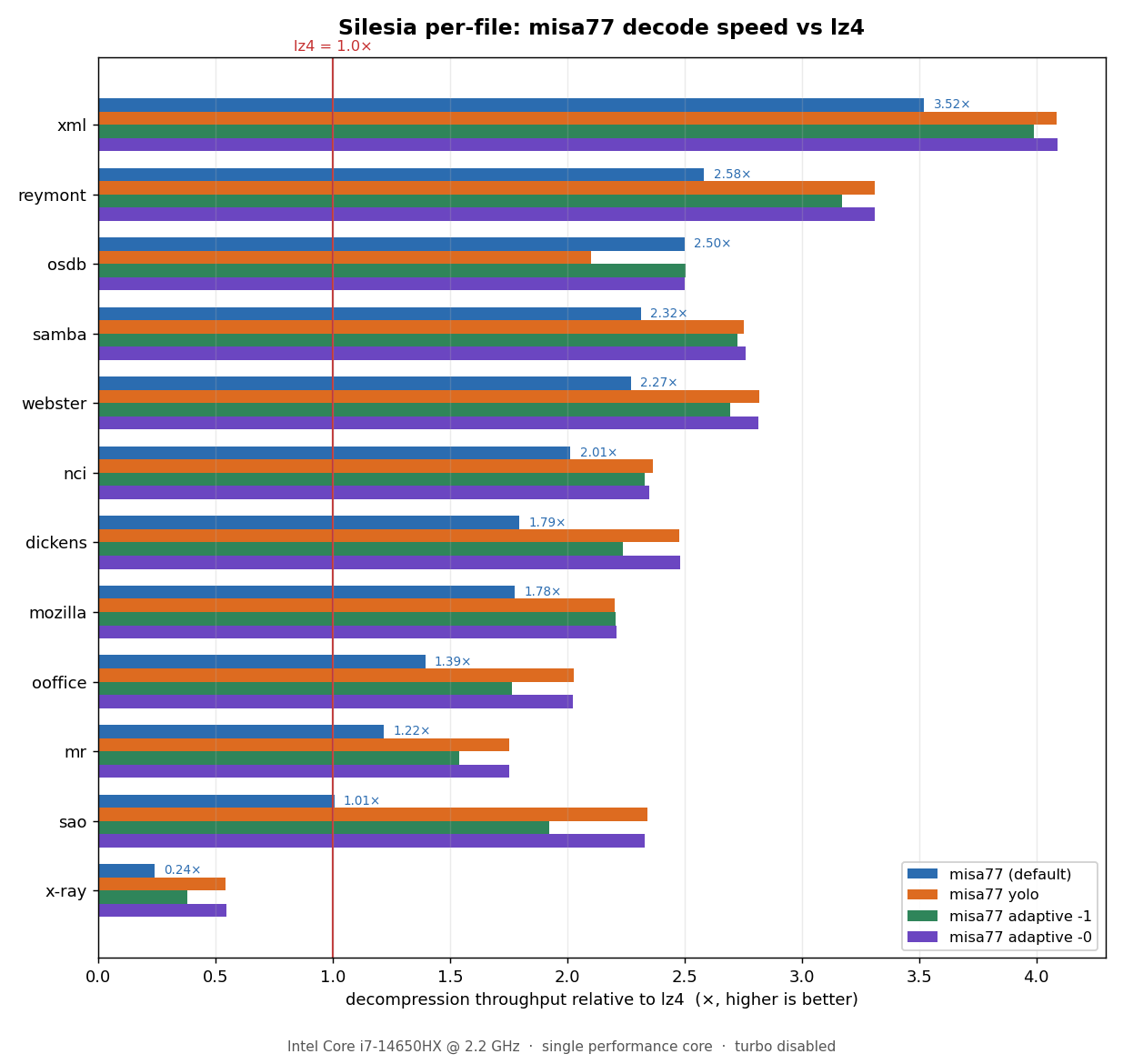
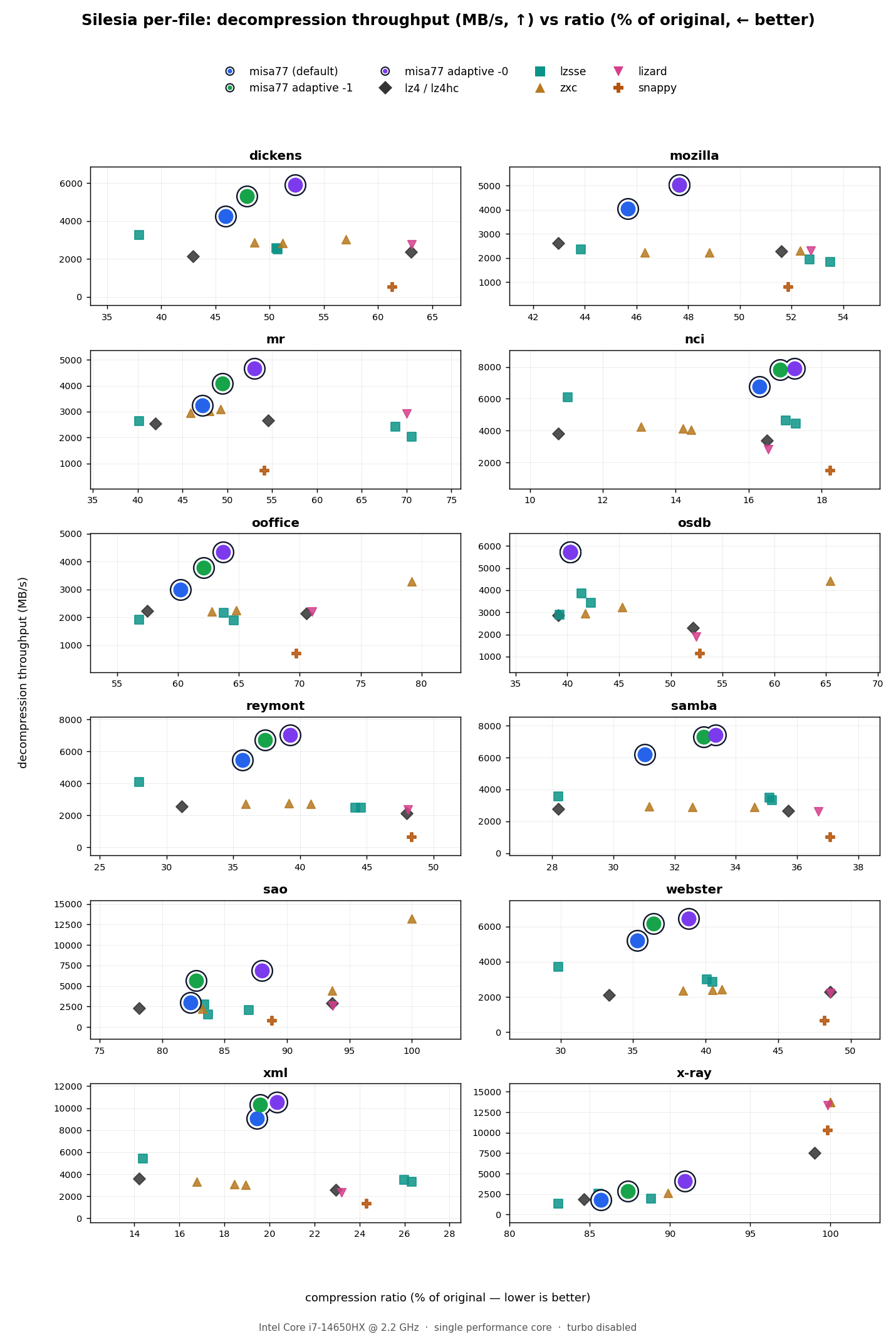
As misa77's performance is quite "spiky" (depending on the shape of the data being compressed), a file-level breakdown for the silesia corpus yields some interesting insights into its performance.
Decode speed relative to lz4
Every misa77 mode decodes faster than lz4 on 11 of the 12 files (some by huge margins). The exception is x-ray, which is highly incompressible (lz4 has a ratio of nearly 1.0 on this file and essentially devolves to a memcpy).
Throughput vs ratio, against popular fast-decode codecs
On the compressible files, misa77 sits on the decode-throughput/ratio Pareto frontier: it decodes fastest while ~matching or beating the ratio of the other fast-LZ codecs. sao and x-ray are exceptions due to the reasons stated before (incompressibility).
I'd be happy to receive feedback/answer queries about misa77 :)
Also I will pre-emptively note that I'm aware of how slow compression is right now, and I don't think it's going to be that hard to speed up (I just need to spend some time on it).
i was thinking about how dial up is basically your phone literally making sounds to your compute, which the computer hears and translates into data.
could you design a system that used multiple phone speakers and multiple microphone pickups to simultaneously get dial-up internet info to speed it up?
if so, how many phone receivers would it take to get modern internet speeds?
Hello everyone , I’m going to start doing btech cse (iot) this year . Im interested in both computer science and physics and I would like to combine them and work in areas like quantum computing . That is my long term goal though I’m not looking forward to be placed directly out of college into quantum computing fields . But at least I would like to go closer to it that is do jobs that involve research or somehow incorporates physics . Can anyone tell me if that’s possible ?If yes , how ? Or a pg degree like MS in computational physics is really required to achieve this ?
what are the things we find difficult to do with technology even though we could do it but it takes time and effort to do it ?
i want to prepare for sr data scientist in MAANG companies. My background is in core ML, deeplearning, nlp etc.
I plan to target in around a year from now.
Does someone have any idea about the interview preparation or someone in these companies who would like to share some experience?
Interviewprep resource:
PracHub: Company specific interview questions
DataLemur: SQL Interview and Data Science Interview questions
StrataScratch: SQL and Python interview
This one took a while, it's probably the longest thing I've written on this blog. I wanted to do a proper end-to-end walkthrough of cmd/compile: real package names, real data structures, diagrams for the AST and SSA CFG, and the flags you actually need (-m, -m=2, GOSSAFUNC, -S) to observe each phase yourself rather than just take my word for it.
Covers the full pipeline: lexer → parser → type checker → IR lowering → SSA construction → optimization passes (inlining, escape analysis, BCE, nil check elimination, register allocation) → architecture-specific code emission.
Hope it's useful — happy to answer questions or push back on anything that looks wrong.
https://github.com/EDrTech/Working-memory-depth-recurrence
https://gitlab.com/erikrudec-group/Working-memory-depth-recurrence
https://codeberg.org/erikrudec/Working-memory-depth-recurrence/
This is a demonstration, in pure python, of a different way of making, well, AI. No backprop, no gradients, no weight transport, only local rules. Everything learns on one graph, and you can run all of it on almost anything.
Have you ever seen an LLM solve the S4 or S5 card shuffle problem? I have something here that trains in under two seconds from scratch and does the full 52 card deck. You hand it a deck and a thousand shuffles, and it tells you the exact order the deck ends up in. It only ever learned from short examples, it was never trained on long sequences.
It can also recover from bad training. If you teach it badly first and it only memorizes, you can teach it properly on top of the same thing, and it starts to actually understand, without forgetting what it already knew.
There are three small demos in here. The first one learns what numbers are by counting piles of things (characters, words, anything), and then it adds, even though it was never shown a single sum. The second learns what each shuffle does to a deck, and then predicts any deck after any number of shuffles, up to the full 52. The third one gets trained quickly and just memorizes, then gets taught properly and comes to understand, on the same memory, with nothing forgotten.
The whole engine is about 60 lines of python and you can read it top to bottom. There is no code in there that knows anything about counting or shuffling. So you do not have to take my word for any of this. You clone it, run it with nothing installed, and read the engine. The demos themselves are not really in question, you can check every number by hand in a few minutes. What I am unsure about is the big claim I am building on top of them.
The claim I have almost fully convinced myself of is that working memory depth recurrence is the backbone of a real, faithful brain abstraction, one that behaves on silicon almost exactly like it behaves in biology.
Working memory depth recurrence is the fix for the bound depth problem. Depth goes from being an impossible problem to a simple series of serial operations, and you get it almost for free. You do not need a two billion dollar cluster, you need some memory and you need to spend compute time instead of brute force compute. It all happens on the one unified graph. The basic operations get taught, and you can watch the higher level rules emerge from there. You teach it to count on piles of things, and it generalizes to the rest.
What I am releasing is the single most important piece for this to work, but it is far from the only thing needed. I built more on top of this backbone to get higher complexity abstractions to emerge, and it did happen, and it stacks very well on top of this.
I might have talked myself into a state where I really believe I have THE thing. So I fully expect people who actually have the AI know how to check whether this amounts to anything. Partly to keep my own sanity, because if this is the thing, it is very weird that I got here through a lot of stubborn ignorance.
I am not a data scientist and not an ML engineer. I know the principles of how it all works, but the terminology in this field is too complicated and it always drags you down the backprop and global rules route. I hated how LLMs behave. I figured they are set up wrong from the ground up, so I set myself the task of doing it properly, and I just stubbornly went against the standard way and deconstructed how my own brain does things.
So check it out and see for yourself. I would really appreciate it if you told me whether this is all a big fever dream of mine, and saved me the further embarrassment. And if it is real, I fully believe this belongs to everyone, and no single person or company should have a monopoly on it.
Thanks!
EDIT: added demo on huggingface: https://huggingface.co/spaces/ErikRudec/Working-memory-depth-recurrence
Hi everyone, I was wondering if anyone here could give me advice on what possible career paths I could go into if my favorite classes are:
-Statistics and Probability
-Calculus 1
-Discrete Math 1
-Discrete Math 2
-Computer Architecture
-Operating Systems
I tried to find the slowest possible way to sum up integers in an array
I recently published paper which claims p=np by solving hamiltonian cycle in polynomial time.
I have already tested code for n=50 and it gives answer in 1 second . I still don't understand why people are not believing in spite of code is showing answer in 1 second. Please run the below java code on your machine and you can verify its polynomial time only.
https://github.com/sanketkulpnp-source/hamiltonian-cycle
This repo contains java code and sample file of 50 vertices. Readme file has all the instructions given. Please check it and verify its time complexity is polynomial time.
Hello everyone, I was getting bored a few months ago and decided to tackle a new personal project, and after having asked around, thought I should make my own bytecode vm. I read up on crafting interpreters and for the past month or two Ive been making my own language, the syntax is pretty standard but I still tried to spice it up in my own way, with things like 'make' for declaring vars and functions and 'pullf' for the stdlib. The language itself is a two pass compiler which compiles to ASTs first and then typechecks those until eventually compiling to bytecode. Ive been working on the project for about 2 months and finally felt it was at least complete enough to share, I still want to do a bunch of stuff like class inheritance and a library for making simple 2d games, but let me know your thoughts on how it looks so far!
https://github.com/NateTheGrappler/OliNat-Programming-Language
I am from Kashmir and I have been selected for BSc Computer Science at IUST. I know it is not considered a top-tier university, so I am a little worried about my future.
I want to know honestly — if I focus on building strong skills (programming, projects, internships, etc.), can I still get good opportunities in the future?
Can someone from a non-top-tier college build a good career in CS? Is it possible to earn well with the right skills, or does the college name matter a lot?
Would really appreciate advice from people in the CS field or those who have gone through a similar situation.
Hi everyone,
I've been working on a personal project called quic-lite, a single-header implementation of QUIC written in C.
The goal is to keep it lightweight, readable, and reasonably close to the QUIC RFCs while avoiding unnecessary complexity.
Current features include:
We've finally launched the very first version of the Stoffel stack, Stoffel 0.1.0.
The team at Stoffel Labs has spent the past year, building an MPC runtime stack from scratched focused on making it easier for developers to integrate privacy into their apps without sacrificing their growth.
Let us know how it goes. Any feedback is appreciated.
I have solved hamiltonian cycle problem in polynomial time which runs in n^6 time complexity in worst case which proves p=np
Here is the link of paper - https://doi.org/10.55041/ISJEM08077
I've been reading about theorem proving, formal methods, symbolic computation, and programming languages, and something keeps bothering me.
They all seem to deal with the same general problem: how abstract mathematics is represented and manipulated by computers.
Things like:
These topics seem to exist across several different fields, but I haven't found one that studies them from a unified perspective.
Am I just missing an existing field, or is there a reason these areas evolved separately?
I'd love to hear from people working in PL, theorem proving, or symbolic computation.
Hey everyone,
I wanted to share something my team and I have been pouring our lives into at Trijna Labs.
There's a lot of talk lately about "Indian AI," but we noticed that most solutions are just wrappers around OpenAI or Anthropic APIs. We wanted to see if we could actually build the core architecture from the ground up—something that could run entirely locally on sovereign hardware without bleeding data to foreign servers.
Instead of standard autoregressive transformers, we’ve been experimenting with custom continuous-learning neural topologies (we call them the ARS and OSM engines). The goal is to drastically reduce GPU compute costs through topological entropy routing.
We finally got our engines stable enough to run through the official EleutherAI lm_eval harness for GSM8K and the LiveBench framework.
Honestly, we were nervous, but the early numbers are really encouraging:
We know we still have a massive mountain to climb to scale this globally, but seeing a homegrown architecture hit these numbers on local hardware feels like a huge win for us.
We uploaded our full methodology, exact dataset hashes, and reproducibility commands to our dev log here if any of you want to dig into the math or rip it apart: https://trijnalabs.tech/news
We are a small team trying to do something insanely difficult, so we’d honestly love any brutal feedback, architectural advice, or questions you guys have.
Thanks for reading!
{kind=link}
{kind=link}